Flights in Location History

I wanted to find all of my flights in my Google Location History, which I've had collecting my phone's GPS location nonstop for 14 years. First, I exported my location history from Takeout. This provides Records.json. Let's turn that into a CSV file to make it a bit easier (for me) to work with.
import csv
import json
with open('Records.json') as json_file:
data = json.load(json_file)
with open('Records.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['timestamp', 'latitude', 'longitude'])
for location in data['locations']:
timestamp = location['timestamp']
try:
latitude = location['latitudeE7'] / 1e7
longitude = location['longitudeE7'] / 1e7
except KeyError:
continue
writer.writerow([timestamp, latitude, longitude])
In my case, this yields a ~million row CSV.
The problem to be solved here is: What is a flight? We don't get altitude information, and even if we did, phones are typically not collecting GPS during flights.
I chose to consider that a flight is a subsequent pair of locations with a travel speed between them of more than 150 mph.
This yielded very noisy results - quite often, I "travel" a couple hundred feet or so in a fraction of a second, because of the noise associated with the input data.
I then decided to filter the input data - instead of using all of it, I would use at most one row per hour (I don't take any flights lasting under that anyway). (I also elected to exclude any speeds over 800 mph, assuming those would be spurious; though the former change came after the latter, and I suspect now that the latter is unnecessary given the time filtering.)
This gave almost perfect results. The only problems were:
- One one particular day, I kept jumping back and forth between Minneapolis and Chicago because of a WiFi-based fix, but not quite quickly enough to hit the filter. Rather than complicate the code further I just removed the small handful of offending data points by hand.
- I didn't have my phone in airplane mode on a few flights, so I ended up with a few enroute points.
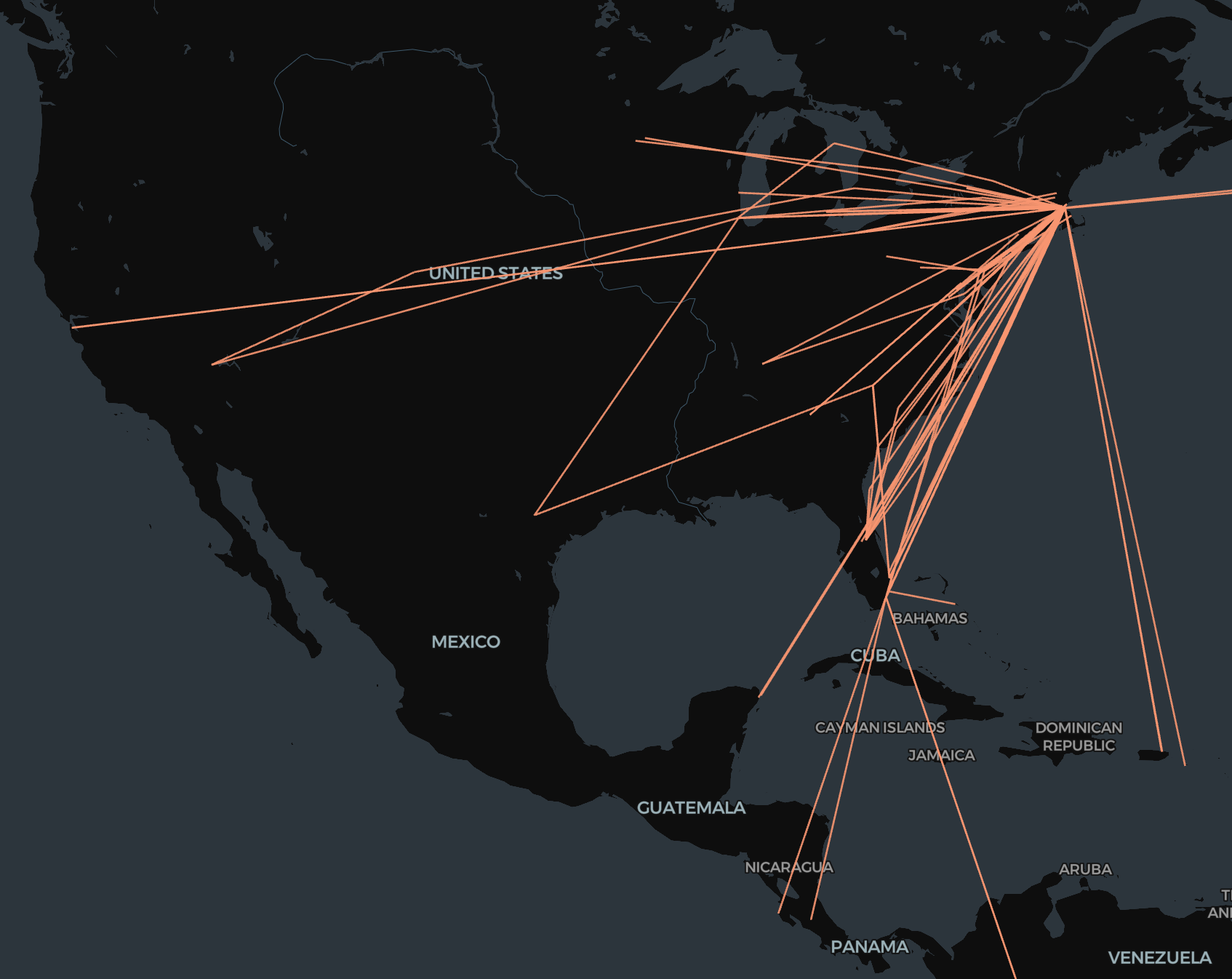
Here's the result (visualized using the fabulous kepler.gl) and code.
N.B. This data is changing to be on-device-only, though it is still exportable as json from Maps on the device.
import pandas as pd
from geopy.distance import geodesic
def read_csv(file_path):
data = pd.read_csv(
file_path, header=None, names=["timestamp", "latitude", "longitude"]
)
data["timestamp"] = pd.to_datetime(data["timestamp"], utc=True, errors="coerce")
data.dropna(subset=["timestamp"], inplace=True)
return data
def filter_rows(data):
data = data[(abs(data["latitude"]) >= 0.01) & (abs(data["longitude"]) >= 0.01)]
filtered_data = []
last_accepted_time = None
for index, row in data.iterrows():
if (
last_accepted_time is None
or (row["timestamp"] - last_accepted_time).total_seconds() >= 3600
):
filtered_data.append(row)
last_accepted_time = row["timestamp"]
return pd.DataFrame(filtered_data).reset_index(drop=True)
def calculate_speed(row1, row2):
time_diff = (
row2["timestamp"] - row1["timestamp"]
).total_seconds() / 3600 # time difference in hours
distance = geodesic(
(row1["latitude"], row1["longitude"]), (row2["latitude"], row2["longitude"])
).miles
speed = distance / time_diff
return speed
def find_high_speed_changes(filtered_data):
high_speed_changes = []
for i in range(len(filtered_data) - 1):
row1 = filtered_data.iloc[i]
row2 = filtered_data.iloc[i + 1]
speed = calculate_speed(row1, row2)
if 150 < speed <= 800:
high_speed_changes.append((row1, row2))
return high_speed_changes
def write_high_speed_changes_to_csv(high_speed_changes, output_file):
high_speed_data = []
for row1, row2 in high_speed_changes:
speed = calculate_speed(row1, row2)
high_speed_data.append(
[
row1["timestamp"],
row1["latitude"],
row1["longitude"],
row2["timestamp"],
row2["latitude"],
row2["longitude"],
speed,
]
)
high_speed_df = pd.DataFrame(
high_speed_data,
columns=[
"Timestamp1",
"Latitude1",
"Longitude1",
"Timestamp2",
"Latitude2",
"Longitude2",
"Speed",
],
)
high_speed_df.to_csv(output_file, index=False)
def main():
input_file_path = "input.csv"
output_file_path = "high_speed_changes.csv"
data = read_csv(input_file_path)
filtered_data = filter_rows(data)
high_speed_changes = find_high_speed_changes(filtered_data)
write_high_speed_changes_to_csv(high_speed_changes, output_file_path)
if __name__ == "__main__":
main()